在余老师带你学习大数据系列课程的第六章第二节中,我们将深入探讨Spark编程模型与其基本架构,这是理解Spark如何实现快速大数据处理的关键。Spark之所以能在大数据领域脱颖而出,不仅因其卓越的性能,更得益于其精心设计的编程模型和高度可扩展的架构。本节将系统性地剖析这两大核心要素,帮助读者构建清晰的知识框架。
Spark编程模型:简化并行计算
Spark编程模型的核心抽象是弹性分布式数据集(RDD,Resilient Distributed Dataset)。RDD是一个不可变、可分区的数据集合,能够跨集群节点并行处理,并具备容错能力。这种模型将数据处理逻辑转化为一系列转换(Transformations)和行动(Actions)操作,极大简化了分布式编程的复杂度。
核心操作类型:
1. 转换(Transformations):如map、filter、groupByKey等,它们基于现有RDD创建新的RDD,具有惰性求值特性,即不会立即执行,而是记录转换关系,直到遇到行动操作才触发实际计算。
2. 行动(Actions):如count、collect、saveAsTextFile等,它们触发计算并返回结果或输出数据,是作业执行的起点。
通过RDD及其操作,开发者可以像编写本地集合程序一样编写分布式代码,而无需深入考虑数据分布、节点通信等底层细节。Spark在RDD基础上发展了更高级的DataFrame和Dataset API,提供结构化数据语义和优化能力,进一步提升了开发效率与执行性能。
Spark基本架构:协同工作的组件生态
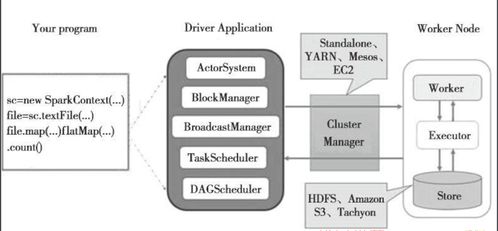
Spark采用主从(Master-Slave)架构,其核心组件协同工作,以实现高效的资源管理和任务执行。主要组件包括:
- Driver Program(驱动程序):
- 作为用户程序的入口点,负责定义RDD及其转换/行动操作。
- 将用户程序转化为有向无环图(DAG),并通过DAG调度器将DAG分解为多个阶段(Stages)和任务(Tasks)。
- 与集群管理器通信,申请资源并协调任务执行。
- Cluster Manager(集群管理器):
- 负责集群资源的统一管理与分配。Spark支持多种集群管理器,包括Standalone(Spark自带)、Apache Mesos和Hadoop YARN。
- 根据Driver的请求,为应用分配Executor资源。
- Executor(执行器):
- 在集群的工作节点上运行的进程,每个应用有独立的Executor。
- 负责执行Driver分配的具体任务,包括数据计算和存储。
- 将缓存数据保存在内存或磁盘中,加速迭代计算。
任务执行流程:
- Driver将用户程序解析为DAG,并划分Stage(基于宽依赖划分边界)。
- Driver通过集群管理器启动Executor。
- Driver将Task分发给对应的Executor执行。
- Executor执行Task,并将结果或状态反馈给Driver。
- Driver收集最终结果或完成输出操作。
架构优势与数据处理效能
Spark架构的核心优势在于其内存计算与DAG调度优化。通过将数据尽可能保留在内存中,Spark避免了MapReduce等框架频繁的磁盘I/O开销,使得迭代算法和交互式查询速度提升数十倍。DAG调度器能够优化任务执行计划,例如进行流水线优化,将多个窄依赖操作合并为一个Stage执行,减少中间结果落盘。
Spark生态提供了Spark SQL(结构化数据处理)、Spark Streaming(流计算)、MLlib(机器学习)和GraphX(图计算)等库,在统一编程模型下支持多样化的数据处理场景,实现了“一站式”大数据分析。
###
掌握Spark编程模型与基本架构,是高效利用Spark进行大数据处理的基石。编程模型通过高层抽象隐藏分布式复杂性,让开发者聚焦业务逻辑;而分层、协同的架构设计,结合内存计算与智能调度,为快速处理海量数据提供了坚实支撑。在后续学习中,我们将基于此基础,深入实践如何利用Spark API解决实际数据处理问题,充分发挥其在大数据时代的威力。