在当今信息爆炸的时代,如何从海量数据中高效地提取、组织并洞察知识,成为各行各业面临的共同挑战。知识图谱作为一种结构化的语义知识库,以其强大的关联分析能力和直观的可视化表现形式,正在成为解决这一问题的关键技术。本文将以一个典型的项目流程为例,详细介绍如何从网络数据抓取开始,一步步构建、存储并最终可视化一个知识图谱,涵盖爬虫技术、数据处理、数据库存储与可视化展现的全过程。
第一步:数据获取——定向网络爬虫
构建知识图谱的第一步是获取原始数据。对于公开的网络资源,如技术博客、百科站点等,编写定向爬虫是常见且高效的方法。以CSDN博客为例,我们可以使用Python的requests、BeautifulSoup或Scrapy框架来抓取目标文章。
关键任务包括:
1. 确定目标与范围: 明确需要采集的领域,例如“人工智能”、“大数据”或“后端开发”相关的博客。
2. 分析页面结构: 解析博客列表页和详情页的HTML结构,定位标题、正文、作者、标签、发布时间等关键信息的CSS选择器或XPath。
3. 编写爬虫程序: 实现自动翻页、请求去重、异常处理(如反爬机制应对、网络超时)等功能,并遵守网站的robots.txt协议,合理设置请求间隔,做到友好爬取。
4. 数据初步清洗: 在抓取过程中或之后,立即去除HTML标签、无关广告文本、空白字符等,将非结构化文本转化为相对规整的纯文本数据。
第二步:数据处理与知识抽取
获取的原始文本数据需要经过深度处理,才能提炼出构成知识图谱的“实体”和“关系”。这是构建图谱的核心环节。
核心流程如下:
1. 实体识别: 利用自然语言处理技术,从博客正文、标题和标签中识别出关键实体。例如,人名(专家、作者)、技术术语(如“TensorFlow”、“Spark”)、组织机构、项目名等。可以采用基于规则的方法、预训练模型(如BERT、ERNIE)或现有工具库(如HanLP、Stanford NLP)。
2. 关系抽取: 确定实体之间的语义关系。例如,“作者-撰写-博客”、“技术A-相似于-技术B”、“技术-属于-领域”。这可以通过分析句法结构、依赖关系或使用关系分类模型来实现。对于技术博客,关系常常隐含在行文之中(如“对比”、“基于”、“应用于”)。
3. 属性抽取: 为实体补充属性信息,如技术的发布日期、作者的单位、博客的阅读量等。
4. 知识融合与消歧: 将不同来源或不同表述的同一实体进行合并(如“机器学习”和“ML”指向同一概念),并解决同名实体歧义问题(如“苹果”公司 vs. “苹果”水果)。
经过此步骤,我们得到了结构化的三元组数据集合:(头实体,关系,尾实体) 或 (实体,属性,值)。
第三步:数据存储——图数据库的选择与应用
知识图谱的本质是图结构数据,因此使用专门的图数据库进行存储和查询是最佳选择。Neo4j是目前最流行的原生图数据库之一。
存储操作要点:
1. 设计图模式: 根据抽取出的实体、关系和属性,设计节点标签、关系类型和属性键。例如,创建Technology、Author、Blog等节点标签,以及WROTE、MENTIONS、RELATED_TO等关系类型。
2. 数据导入: 将上一步处理好的三元组数据,通过Neo4j的Cypher查询语言批量导入数据库。例如:`cypher
CREATE (a:Author {name: '张三'}), (b:Blog {title: '知识图谱入门'})
CREATE (a)-[:WROTE {time: '2023-10-01'}]->(b)`
- 建立索引: 对经常查询的实体属性(如
name、title)建立索引,以大幅提升查询速度。
使用图数据库的优势在于,它能够高效地执行复杂的关联查询(如多跳查询、路径查找),这是传统关系型数据库难以胜任的。
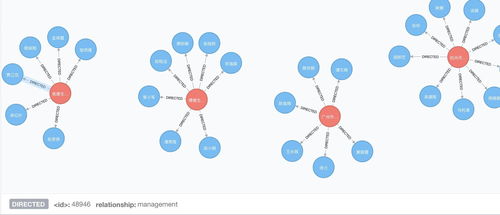
第四步:知识可视化与交互式探索
将存储在数据库中的知识图谱直观地展示出来,是发挥其价值的关键。可视化有助于快速发现模式、洞察关联。
实现方式:
1. 后端API: 使用Python的Flask或FastAPI框架搭建一个Web服务后端。该后端负责连接Neo4j数据库,接收前端的查询请求(例如“展示与‘神经网络’相关的所有技术和博客”),执行Cypher查询,并将结果以JSON格式返回给前端。
2. 前端可视化: 使用专业的图可视化JavaScript库,如ECharts、G6、Cytoscape.js或D3.js。这些库能够将节点和关系数据渲染成可交互的力导向图、网状图等。用户可以点击节点查看详情、拖拽布局、放大缩小、高亮关联路径等。
3. 集成与分析: 在可视化界面中,可以集成简单的分析功能,如计算节点的度中心性(重要性)、查找两个实体之间的最短路径、进行社区发现(聚类)等,从而挖掘更深层的知识。
应用与展望
通过以上流程构建的知识图谱,可以应用于多种场景:
- 智能搜索与推荐: 超越关键词匹配,实现语义搜索(如搜索“深度学习框架”,能返回TensorFlow、PyTorch等相关实体及其关联内容),并基于图谱关联进行内容推荐。
- 领域知识梳理: 快速构建某个技术领域(如“云原生”)的知识全景图,厘清技术栈、工具链和核心概念之间的关系。
- 趋势分析: 结合时间属性,分析不同技术热度的演变趋势及关联技术的共现规律。
****,从爬虫抓取、信息抽取到图数据库存储与可视化,构建知识图谱是一个系统性的工程。它融合了网络爬虫、自然语言处理、数据库技术和数据可视化等多个领域的技术。随着技术的不断发展,自动化抽取的精度、大规模图谱的存储计算效率以及交互式可视化的体验都将持续提升,使得知识图谱在更广泛的领域发挥其“智慧大脑”的作用。