技术交底书是保障技术方案准确、高效实施的关键文档,对于数据处理这类逻辑复杂、细节繁多的领域尤为重要。一份高质量的数据处理技术交底书,不仅是开发与执行团队之间的沟通桥梁,也是项目可追溯、可复现的重要保障。本文将系统阐述撰写高质量数据处理技术交底书的核心要素与具体方法。
一、明确交底书的核心目标与受众
在动笔之前,需明确文档的根本目标:确保接收方能够清晰、完整、无误地理解数据处理的需求、逻辑、步骤及注意事项,并能独立正确执行。需明确受众是谁——是数据工程师、算法研究员、业务分析师还是运维人员?针对不同受众,技术深度、业务背景说明的详略应有所调整。
二、结构化内容框架:六大核心模块
一份完整的数据处理技术交底书通常应包含以下模块:
- 项目概述与目标
- 项目背景:简要说明为何要进行此数据处理,解决什么业务或技术问题。
- 处理目标:清晰定义本次数据处理的最终输出物是什么(例如:一张清洗后的用户行为表、一个特征数据集、一份聚合统计报告),以及需要满足的质量标准(如准确性、完整性、时效性要求)。
- 范围与边界:明确说明处理的数据范围(时间范围、数据主体范围等)以及不做处理的例外情况。
- 数据源说明
- 输入数据详述:列出所有输入数据源,包括但不限于:
- 数据表/文件名称、位置(库、表、路径、接口URL)。
- 关键字段清单、数据类型、含义(提供数据字典或样例)。
- 数据更新频率、增量/全量标识。
- 数据质量现状(已知的脏数据、缺失、异常情况)。
- 依赖关系:说明是否存在上游依赖,其就绪条件或触发时机。
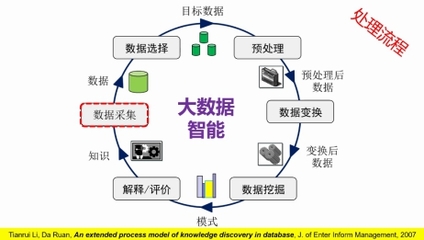
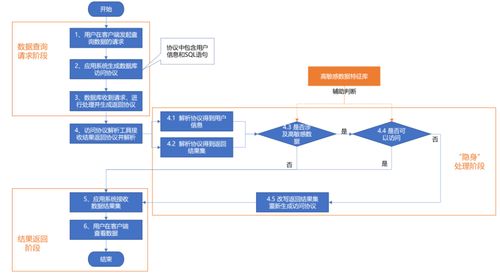
- 数据处理逻辑与流程
- 总体流程图:使用流程图(如UML活动图、简单的方框图)直观展示处理的整体步骤与分支。
- 分步详细逻辑:这是交底书的核心。对流程图中每一步进行细化说明:
- 步骤编号与名称。
- 操作描述:具体做什么(如:关联、过滤、聚合、计算新字段、格式转换)。
- 逻辑规则:用公式、伪代码或严谨的自然语言描述业务规则与计算逻辑。例如:“
用户等级 = IF(累计消费金额 >= 1000, 'VIP', IF(累计消费金额 >= 500, '高级', '普通'))”。
- 输入与输出:明确本步的输入数据与产出中间数据。
- 核心算法/模型说明:若涉及复杂算法或机器学习模型,需说明其原理、关键参数、版本及输入输出格式。
- 输出结果规范
- 输出物定义:详细描述最终输出数据的:
- 存储位置与格式(如:Hive表
dw.user<em>profile</em>final,Parquet格式)。
- 表结构(字段名、类型、注释,特别是新增或含义变更的字段)。
- 数据分区方式(如按
dt日期分区)。
- 数据质量校验规则:提供用于验证输出数据是否正确的SQL检查语句或质量指标(如:记录数波动范围、关键字段非空率、值域范围、与历史数据的一致性对比方法)。
- 异常处理与容错机制
- 常见异常场景:预判可能出现的错误(如:数据源缺失、数据格式异常、计算溢出、关联键丢失)。
- 处理预案:针对每种异常,明确处理方式(如:告警并中止、使用默认值填充、记录至异常日志表供人工排查)。
- 重跑与回滚方案:说明任务失败后如何重新处理,以及如何撤销错误输出。
- 环境、资源与执行说明
- 运行环境:指明所需的计算环境(如:Spark集群版本、Python环境及依赖包列表)。
- 调度与依赖:说明任务调度方式(如:Airflow DAG ID、Crontab表达式)、上游依赖任务。
- 性能与资源预估:对关键步骤的数据量、处理耗时、所需内存/CPU进行预估,帮助执行方配置资源。
- 操作指令:提供可复现的、清晰的执行命令或脚本入口,并注明关键参数。
三、撰写原则与技巧
- 清晰准确,无歧义:避免使用“大概”、“可能”等模糊词汇,技术术语定义清晰。
- 图文并茂,层级分明:多用流程图、示意图、表格和列表,结构使用标题层级清晰分隔。
- 实例化说明:对于复杂逻辑,提供输入输出的具体数据样例,直观演示转换过程。
- 版本管理:文档自身应有版本号和修订历史,记录每次变更的内容、原因及日期。
- 可测试性:文档描述的逻辑应具备可验证性,最好能提供小规模测试用例或验证查询。
四、评审与维护
初稿完成后,应组织相关方(如需求方、开发、测试、运维)进行评审,根据反馈查漏补缺。数据处理逻辑变更时,技术交底书必须同步更新,确保其始终是当前处理方案的唯一权威描述。
撰写高质量的数据处理技术交底书是一项需要严谨与细致的工作。它不仅是任务的说明书,更是团队知识沉淀和传承的载体。投入时间打造一份结构清晰、内容完备、描述精准的交底书,将极大地降低沟通成本、提升处理准确率与团队协作效率,为数据产出的可靠性与价值实现奠定坚实基础。